I [mentioned earlier] that the licenses have this 3 layer design. I spent more time explaining that than I care to think about, and was still doing so in 2011 as I prepared to leave CC.
I just found the Github repo and resurrected a visualization of the license layers that Alex and I created.
I told you I was really into figuring out CSS.
I wonder who Eldarion sees as competitors for TS/Teams. I think it's something like Quip. They're not really in the same space, but I think they're trying to solve the same problem: make it easier for teams/companies to write things down and have a conversation.
I was in a group show in Oakland in May entitled "We Are the Bridge". The show focused on how artists envision themselves and their work as a bridge between cultures. I had two pieces in the show, which are arguably the most personal work I've done. They came about as I reflected on my upbringing in a conservative, fundamentalist environment, and how that was impacted when I came out. They were my bridge back to spirituality and faith.
Part of the submission process required me to write a personal statement, and a statement about each work. That was challenging, but also really clarifying for me. It helped me frame some of the feelings that I had around the work. When I was in the studio a couple weeks ago, I worked on a small "practice" plate. (A practice plate for me is just something I make in order to practice a technique, or see what comes out. I try not to let myself get too attached to any outcome.) In this case it was a map grid of West Lafayette, Indiana, where I first went to college.
After I pulled the first print, I stood and looked at the image. And I realized that there's more depth there than I expected: the area of the map I chose to represent has many meanings and memories. It occurred to me that writing about those would probably help develop more work, more depth.
I've been thinking for a while that I'd like a way to share my work in progress with a wider audience. I think people are interested in process, and I think it'd be good practice for me to share more often. And my portfolio site is almost always out of date.
So once again I write something here about how maybe TS is the right tool for something I sort of want to do. We'll see if I give it a shot.
At Remind things are even more involved. We're going to need to translate:
- Android and iOS native applications
- Angular web application
- Text content in our Rails API
- Small messages in Node.js and Golang based services
- Help center content store in Zendesk
- Life-cycle emails sent via customer.io
That does make me wonder, though, is the "stream" the first class citizen in a branch-enabled world, or is it the "thought"? Maybe it's only a matter of rendering, but I sort of hope there's a way to see the world as a series of branching conversations.
I've realized as I'm writing this that I have this assumption that TS could replace the blogging tool that I've been using (Pelican, which replaced Tinkerer, which replaced WordPress, which replaced... Moveable Type??). Maybe TS is something different. Maybe it's a different kind of writing.
Is Thought Streams replacing blogging for its users? Are people using TS as a way to draft longer pieces?
DynamoDB is a hosted NoSQL database, part of Amazon AWS. We're using it as the primary data store for our messaging system.
Dynamo pricing is based on three factors: dataset size, provisioned read capacity, and provisioned write capacity. Write capacity is by far the most expensive (approx 3x as expensive as reads).
The provisioned I/O capacity is interesting: as you reach your provisioned capacity, calls to Dynamo being returning HTTP 400 responses, with a Throttling status. This is the cue for your application to back off and retry. I'll come back to throttling shortly.
When you start out -- say with no data, and 3000 reads and 1000 writes per second -- all of your data is in a single partition. As you add data or scale up your provisioned capacity, Amazon transparently splits your data into additional partitions to keep up. This is one of the selling points: that you don't have to worry about sharding or rebalancing.
It's not just your data that gets split when you hit the threshold of a partition: it's the provisioned capacity, as well. So if you have your table provisioned for 1000 writes per second and 3000 reads per second, and your data approaches the capacity of a single partition, it will be split into two partitions. Each partition will be allocated 500 writes per second and 1500 reads per second.
DynamoDB works best with evenly distributed keys and access, so that shouldn't be a problem. But it could be: if you try to make 600 writes per second to data that all happens to live in a single partition, you'll be throttled even though you think you have excess capacity.
Provisioning that I/O capacity is important to get right: it's not sufficient to turn the dial all the way to 11 from day 1. That's because Dynamo will also split a partition based on provisioned I/O capacity. A single a partition is targeted roughly at the 1000/3000 level, so doubling that to 2000/6000 will also cause a split, regardless of how much data you have.
Splits due to provisioned I/O capacity -- particularly when you dramatically increase the capacity for a high volume ingest -- are the source of dilution.
"Dilution" is the euphemism Amazon uses to refer to a situation where the provisioned I/O is distributed across so many partitions that you're effective throughput is "diluted". So why would this happen? Well, remember that a partition can be split when either data size or provisioned I/O increases.
Partitions only split, they are never consolidated.
So if you decide that you want an initial ingest to complete at a much faster rate than your application is going to sustain in production and increase the provisioned I/O to match, you're effectively diluting your future I/O performance by artificially increasing the number of partitions.
Whomp whomp.
Something that's bitten me a few times -- although I'm slowly internalizing it -- is the fact that while *Person is a pointer to a Person struct, *Individual is not a pointer to "any type implementing Individual".
*Individual is a pointer to the interface itself.
A parameter that's an interface type doesn't tell you anything about whether it's a pointer or a copy. Either can implement the interface, depending on how the methods are declared.
Streams by this user that have been favorited by others.
CC
I [mentioned earlier] that the licenses have this 3 layer design. I spent more time explaining that than I care to think about, and was still doing so in 2011 as I prepared to leave CC.
I just found the Github repo and resurrected a visualization of the license layers that Alex and I created.
I told you I was really into figuring out CSS.
In 2003, mozdev.org was providing free hosting to Mozilla related projects, and that seemed to be a better bet than continuing to run my own CVS server.
And... look at that, MozDev CVS is still up and running. I did not expect to ever type brew install cvs on this machine.
Thinking about it now, there were a bunch of new things to learn in building mozCC and CC Validator.
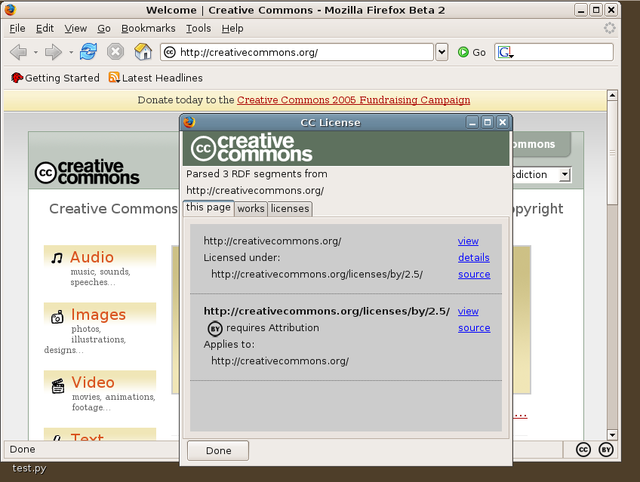
To make the first version of mozCC work I had to figure out how to write a Mozilla extension. My recollection from years later is that this was sort of a pain. I didn't know it at the time, but I was learning about:
- URIs
- RDF
- Triples/Graphs
- XUL
- "web services" (I'd been building web tools for teachers at my day job for Canterbury School, but running them on my own server, and publicly, was a different story.)
Thinking about it now, those tools had a lot of rough edges, but there was also this seductively consistent worldview to them. For example, XUL included RDF triple-matching support, so the UI you see above outlining the license on the CC site was generated from the triples extracted from the HTML comment.
I was also really into figuring out CSS.
I was pretty proud of my mozCC slogan that appeared on the early project website:
At least twice as good as view:source.
So those first efforts were all about making that license descriptor less fragile and easier to discover.
The Validator fetched a URI, parsed the source, and tried to find the comment. If it found it, it tried to parse it as RDF, and then match the license information. Any parsing errors were spit back to the user.
mozCC did something similar, albeit with the current page in the browser. It ran on pretty much every page, and when it found the license, it displayed an icon in the status bar.
When you visited the license chooser in 2003, you answered three questions and were presented with some HTML you could paste into your web page. That HTML contained a comment in it, containing the machine readable license RDF/XML.
There were a few reasons for the comment approach. My recollection is that at the time there wasn't really a way to reliably embed structured data in HTML. This was before Microformats, Microdata, RDFa, etc. People occasionally suggested using a META tag, but there were issues with that, as well. (Namely, if you were using a hosted authoring system like Movable Type or Blogger, you usually didn't have control of the head of your document.)
The <!-- comment --> was the recommendation because it worked. It embedded some information, and most tools passed it through unmolested.
CC licenses have been represented three ways from the beginning. There's the legal text, the human readable "deed", and the machine readable RDF. If the legal text is what a lawyer would look at to understand the license, the RDF is what software would look like to understand it in a coarse grained fashion. It expressed the licenses in terms of permissions, requirements, and prohibitions, and contained pointers to things like translations, legal text, and version information.
For example, CC BY 4.0 has the following assertions:
<cc:License rdf:about="http://creativecommons.org/licenses/by/4.0/">
<cc:requires rdf:resource="http://creativecommons.org/ns#Notice"/>
<cc:requires rdf:resource="http://creativecommons.org/ns#Attribution"/>
<cc:permits rdf:resource="http://creativecommons.org/ns#Reproduction"/>
<cc:permits rdf:resource="http://creativecommons.org/ns#Distribution"/>
<cc:permits rdf:resource="http://creativecommons.org/ns#DerivativeWorks"/>
</cc:License>
So CC BY 4.0 permits Reproduction, Distribution, and Derivative Works. Exercising those permissions requires Notice (identifying that you're using the work under the license) and Attribution (the original creator information).
This approach laid the groundwork for a lot of interesting possibilities: guidance on combining works, search with re-use in mind, and (later) easy attribution of works.
mozCC
(Take 1)
In November 2003 I shipped the first version of "mozCC", a browser plugin for Mozilla Firebird that detected license metadata in pages as you browsed and showed a little (CC) icon in your status bar. This wound up being pretty interesting, and is a good segue to talking about why CC had technology challenges in the first place.
(Digging through the archive is also an instructive lesson on how hard it is to maintain links for over a decade, despite your best intentions and efforts. The content on my site is still mostly there, but the paths have changed slightly.)
Reading the October 2013 cc-metadata archive is like unearthing an old diary. I was having fun, people I hadn't ever met were using software I was writing, and I was learning fast by necessity. When Mike gave me some suggestions -- nicely wrapped in an encouraging sandwich -- I had to figure out that URIs are not URLs, and just wtf that meant.
I'll have to see if I can find the source tree for the original CC Validator (a similarly defunct GSOC rewrite exists in the CC Archive).
I wonder who Eldarion sees as competitors for TS/Teams. I think it's something like Quip. They're not really in the same space, but I think they're trying to solve the same problem: make it easier for teams/companies to write things down and have a conversation.
I worked at Canterbury School from 2001-mid 2004, splitting my time between teaching, building tools for teachers, and IT work (networking, getting machines imaged, and yes, sigh, help desk). At the time Canterbury required all high school freshmen to take a quarter of computer programming. When I started working at Canterbury mid-year, the class was taught in Java, which had superseded C and Pascal over the years.
In the summer of 2001 Naomi and I went to LinuxWorld and attended Guido van Rossum's Python tutorial. (I think the presentation was nearly identical to the one he presented in 2002 in NYC). On the flight home Naomi started drafting what Intro exercises would look like in Python, and the conclusion was obvious: this was a much better language to teach in, especially when this was the last programming course many of our students would take. I worked on it some more when we got home, and in the fall we rolled out one section of a Python-based Intro class.
We were rolling out Linux servers running Samba as backup domain controllers, and our home-rolled imaging system was strung together with bash, if memory serves.
I spent a lot of time reading Slashdot. (Tuition dollars well spent, no doubt.) And that's probably how CC first crossed my radar.
"Technical Challenges"
In the fall of 2003 Mike Linksvayer, CC's CTO, posted a list of "technical challenges" on the Creative Commons blog. These were projects they wanted to do, but simply didn't have the capacity for. Things they thought would help support the ecosystem, and hoped people in the community would work on.
In a pattern that's repeated itself since then, I started poking at one to see if I could make it dance. I started with a license validator web application, and announced it in October 2003. This is in the midst of back to school, both for Canterbury and myself -- I'd gone back to college that fall, and I was in that making zone where I'd work on figuring out CGI headers while watching TV with my partner, or try to fix "just one bug" over lunch at work, and look up to realize it was 2 in the afternoon. I was having fun.
Does ThoughtStreams have a public API? I was on the bus this evening and thought that it'd be convenient to be able to upload media and a quick thought along with it, directly from my device.
I spent seven years working at Creative Commons, first as a software engineer, and later as CTO. I've been gone four years and still think of that work as some of the best I've done. And I sometimes wonder if people know just how much was going on behind the scenes at CC, what made it so technically exciting for a while. While I still remember, I thought it might be interesting to write things down.
This would really reduce my perceived risk for devoting time to TS. I wonder if there's been any progress?
I don't know why I feel like it's scary or a bad idea, but there's something there. Like, for reflections and one offs, not a big deal. If I wanted to seriously talk about my artistic practice, that feels like something I want some freedom with. (Although, I must admit that lately I sometimes feel like a luddite with this sort of view, especially with the rise of Medium.)
Yes, we plan to support CNAMEs for ThoughtStreams.
I was in a group show in Oakland in May entitled "We Are the Bridge". The show focused on how artists envision themselves and their work as a bridge between cultures. I had two pieces in the show, which are arguably the most personal work I've done. They came about as I reflected on my upbringing in a conservative, fundamentalist environment, and how that was impacted when I came out. They were my bridge back to spirituality and faith.
Part of the submission process required me to write a personal statement, and a statement about each work. That was challenging, but also really clarifying for me. It helped me frame some of the feelings that I had around the work. When I was in the studio a couple weeks ago, I worked on a small "practice" plate. (A practice plate for me is just something I make in order to practice a technique, or see what comes out. I try not to let myself get too attached to any outcome.) In this case it was a map grid of West Lafayette, Indiana, where I first went to college.
After I pulled the first print, I stood and looked at the image. And I realized that there's more depth there than I expected: the area of the map I chose to represent has many meanings and memories. It occurred to me that writing about those would probably help develop more work, more depth.
I've been thinking for a while that I'd like a way to share my work in progress with a wider audience. I think people are interested in process, and I think it'd be good practice for me to share more often. And my portfolio site is almost always out of date.
So once again I write something here about how maybe TS is the right tool for something I sort of want to do. We'll see if I give it a shot.
At Remind things are even more involved. We're going to need to translate:
- Android and iOS native applications
- Angular web application
- Text content in our Rails API
- Small messages in Node.js and Golang based services
- Help center content store in Zendesk
- Life-cycle emails sent via customer.io
As background: I first worked on i18n during the Zope 3 sprints at PyCon 2003 (I think that's the right year), working with Stefan and Jim on zope.i18n.
At Creative Commons, I worked on i18n for the license chooser, licenses, wiki, etc, as well as the desktop apps we wrote for a while. Lots of gnarly bits in there, but still mostly gettext based. I think we were localizing the deeds into 40-50 languages when I left, and had done some serious work to accept translation suggestions from the community with approval/acceptance by our partner organizations. Jinja, ZPT, content negotiation, lots of fun stuff.
At Eventbrite I worked on i18n again, again with Python and gettext. Mako templates + javascript, as well as figuring out how multiple TLDs would work (ie, eventbrite.fr should start in French (fr-FR), but what happens if you want eventbrite.fr in Spanish? The answer is non-obvious, and we worked really hard to get it close to right. The real answer is "Don't do multiple TLDs; it's sort of dumb.")
I once again find myself working on an i18n/l10n (internationalization/localization) effort, so I figure I may as well document how things evolve for public consumption.
I'd love a "fast draft" mode. Instead of clicking "Publish" after each thought (or in my case, pressing Tab-Tab-Tab-Enter, because I'm not a savage), I'd simply press Enter-Enter: closing the paragraph, skipping a line, and starting a new thought.
That does make me wonder, though, is the "stream" the first class citizen in a branch-enabled world, or is it the "thought"? Maybe it's only a matter of rendering, but I sort of hope there's a way to see the world as a series of branching conversations.
"Branching" sounds interesting. I've thought about my ThoughtStreams (my streams?) as a graph almost since the start. I found myself writing on ThoughtStreams the same way I talk to a friend or think about a problem: there are digressions, forks, and often threads come together. I'm hopeful the release of branching will make it possible to do a lot of those.
I've realized as I'm writing this that I have this assumption that TS could replace the blogging tool that I've been using (Pelican, which replaced Tinkerer, which replaced WordPress, which replaced... Moveable Type??). Maybe TS is something different. Maybe it's a different kind of writing.
Is Thought Streams replacing blogging for its users? Are people using TS as a way to draft longer pieces?
So I'm left feeling conflicted: it feels good to be writing online, and it feels like TS does a lot of things "right" (for me). And I find myself wishing I could point a CNAME at it.
And I care about my writing in a way that I guess I don't care about, say, my bookmarks. If Pinboard went under tomorrow, I'd be annoyed, but that probably wouldn't last. It wouldn't take long for a hypothetical TS shutdown -- breaking links that you hope are built to and within any successful service -- to reach the point of clothes-rending angst.
And that's the extreme case, things coming to a halt. Even TS atrophied and a better tool came along, with my work stuck on thoughtstreams.io, the switching cost is harder.

Thoughts by this user that have been liked by others.
Methods in Go can have a struct receiver or a pointer receiver. For example, given a Person struct:
type Person struct {
name string
}
You could implement a Hello() method as either
func (p Person) Hello() string {
return "Hello " + p.name
}
or
func (p *Person) Hello() string {
return "Hello " + p.name
}
The difference between the two is what p is: in the case of the former, p is a copy of the Person struct, and any changes you make won't be reflected in the caller.
In the case of the latter -- where p is a pointer receiver, *Person -- p is mutable, and its contents can be changed. Another difference is that when you use a pointer receiver the contents of p don't need to be copied before executing the Hello() method. This can be really important for large structs.
Something that's bitten me a few times -- although I'm slowly internalizing it -- is the fact that while *Person is a pointer to a Person struct, *Individual is not a pointer to "any type implementing Individual".
*Individual is a pointer to the interface itself.
A parameter that's an interface type doesn't tell you anything about whether it's a pointer or a copy. Either can implement the interface, depending on how the methods are declared.
The interesting thing to me is this:
Thought Streams brought me back to writing online in a way that's very seductive. TS sets the expectation that posts (cards?) can be short, maybe only a sentence, and that takes the pressure to fully develop an idea before you write it down off. And the lack of a character limit takes the pressure to be pithy off. I have enough pressure in my life, so there's no way I'm going to write online if it adds pressure.
"Branching" sounds interesting. I've thought about my ThoughtStreams (my streams?) as a graph almost since the start. I found myself writing on ThoughtStreams the same way I talk to a friend or think about a problem: there are digressions, forks, and often threads come together. I'm hopeful the release of branching will make it possible to do a lot of those.
I'd love a "fast draft" mode. Instead of clicking "Publish" after each thought (or in my case, pressing Tab-Tab-Tab-Enter, because I'm not a savage), I'd simply press Enter-Enter: closing the paragraph, skipping a line, and starting a new thought.
Does ThoughtStreams have a public API? I was on the bus this evening and thought that it'd be convenient to be able to upload media and a quick thought along with it, directly from my device.