I spent seven years working at Creative Commons, first as a software engineer, and later as CTO. I've been gone four years and still think of that work as some of the best I've done. And I sometimes wonder if people know just how much was going on behind the scenes at CC, what made it so technically exciting for a while. While I still remember, I thought it might be interesting to write things down.
I worked at Canterbury School from 2001-mid 2004, splitting my time between teaching, building tools for teachers, and IT work (networking, getting machines imaged, and yes, sigh, help desk). At the time Canterbury required all high school freshmen to take a quarter of computer programming. When I started working at Canterbury mid-year, the class was taught in Java, which had superseded C and Pascal over the years.
In the summer of 2001 Naomi and I went to LinuxWorld and attended Guido van Rossum's Python tutorial. (I think the presentation was nearly identical to the one he presented in 2002 in NYC). On the flight home Naomi started drafting what Intro exercises would look like in Python, and the conclusion was obvious: this was a much better language to teach in, especially when this was the last programming course many of our students would take. I worked on it some more when we got home, and in the fall we rolled out one section of a Python-based Intro class.
We were rolling out Linux servers running Samba as backup domain controllers, and our home-rolled imaging system was strung together with bash, if memory serves.
I spent a lot of time reading Slashdot. (Tuition dollars well spent, no doubt.) And that's probably how CC first crossed my radar.
"Technical Challenges"
In the fall of 2003 Mike Linksvayer, CC's CTO, posted a list of "technical challenges" on the Creative Commons blog. These were projects they wanted to do, but simply didn't have the capacity for. Things they thought would help support the ecosystem, and hoped people in the community would work on.
In a pattern that's repeated itself since then, I started poking at one to see if I could make it dance. I started with a license validator web application, and announced it in October 2003. This is in the midst of back to school, both for Canterbury and myself -- I'd gone back to college that fall, and I was in that making zone where I'd work on figuring out CGI headers while watching TV with my partner, or try to fix "just one bug" over lunch at work, and look up to realize it was 2 in the afternoon. I was having fun.
I'll have to see if I can find the source tree for the original CC Validator (a similarly defunct GSOC rewrite exists in the CC Archive).
Reading the October 2013 cc-metadata archive is like unearthing an old diary. I was having fun, people I hadn't ever met were using software I was writing, and I was learning fast by necessity. When Mike gave me some suggestions -- nicely wrapped in an encouraging sandwich -- I had to figure out that URIs are not URLs, and just wtf that meant.
(Digging through the archive is also an instructive lesson on how hard it is to maintain links for over a decade, despite your best intentions and efforts. The content on my site is still mostly there, but the paths have changed slightly.)
mozCC
(Take 1)
In November 2003 I shipped the first version of "mozCC", a browser plugin for Mozilla Firebird that detected license metadata in pages as you browsed and showed a little (CC) icon in your status bar. This wound up being pretty interesting, and is a good segue to talking about why CC had technology challenges in the first place.
CC licenses have been represented three ways from the beginning. There's the legal text, the human readable "deed", and the machine readable RDF. If the legal text is what a lawyer would look at to understand the license, the RDF is what software would look like to understand it in a coarse grained fashion. It expressed the licenses in terms of permissions, requirements, and prohibitions, and contained pointers to things like translations, legal text, and version information.
For example, CC BY 4.0 has the following assertions:
<cc:License rdf:about="http://creativecommons.org/licenses/by/4.0/">
<cc:requires rdf:resource="http://creativecommons.org/ns#Notice"/>
<cc:requires rdf:resource="http://creativecommons.org/ns#Attribution"/>
<cc:permits rdf:resource="http://creativecommons.org/ns#Reproduction"/>
<cc:permits rdf:resource="http://creativecommons.org/ns#Distribution"/>
<cc:permits rdf:resource="http://creativecommons.org/ns#DerivativeWorks"/>
</cc:License>
So CC BY 4.0 permits Reproduction, Distribution, and Derivative Works. Exercising those permissions requires Notice (identifying that you're using the work under the license) and Attribution (the original creator information).
This approach laid the groundwork for a lot of interesting possibilities: guidance on combining works, search with re-use in mind, and (later) easy attribution of works.
When you visited the license chooser in 2003, you answered three questions and were presented with some HTML you could paste into your web page. That HTML contained a comment in it, containing the machine readable license RDF/XML.
There were a few reasons for the comment approach. My recollection is that at the time there wasn't really a way to reliably embed structured data in HTML. This was before Microformats, Microdata, RDFa, etc. People occasionally suggested using a META tag, but there were issues with that, as well. (Namely, if you were using a hosted authoring system like Movable Type or Blogger, you usually didn't have control of the head of your document.)
The <!-- comment --> was the recommendation because it worked. It embedded some information, and most tools passed it through unmolested.
So those first efforts were all about making that license descriptor less fragile and easier to discover.
The Validator fetched a URI, parsed the source, and tried to find the comment. If it found it, it tried to parse it as RDF, and then match the license information. Any parsing errors were spit back to the user.
mozCC did something similar, albeit with the current page in the browser. It ran on pretty much every page, and when it found the license, it displayed an icon in the status bar.
I was pretty proud of my mozCC slogan that appeared on the early project website:
At least twice as good as view:source.
Thinking about it now, there were a bunch of new things to learn in building mozCC and CC Validator.
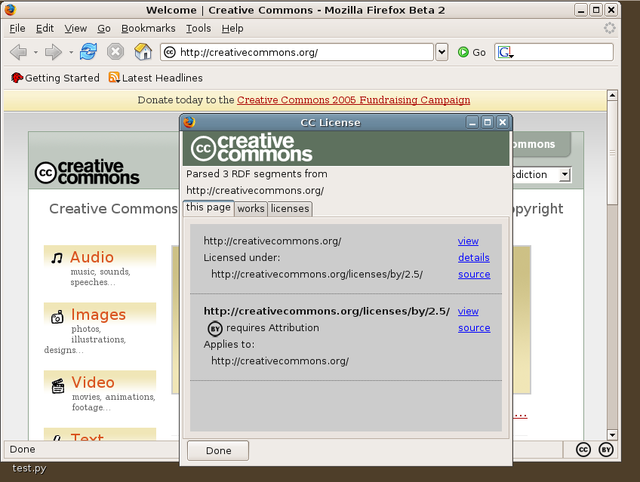
To make the first version of mozCC work I had to figure out how to write a Mozilla extension. My recollection from years later is that this was sort of a pain. I didn't know it at the time, but I was learning about:
- URIs
- RDF
- Triples/Graphs
- XUL
- "web services" (I'd been building web tools for teachers at my day job for Canterbury School, but running them on my own server, and publicly, was a different story.)
Thinking about it now, those tools had a lot of rough edges, but there was also this seductively consistent worldview to them. For example, XUL included RDF triple-matching support, so the UI you see above outlining the license on the CC site was generated from the triples extracted from the HTML comment.
I was also really into figuring out CSS.
In 2003, mozdev.org was providing free hosting to Mozilla related projects, and that seemed to be a better bet than continuing to run my own CVS server.
And... look at that, MozDev CVS is still up and running. I did not expect to ever type brew install cvs on this machine.
I [mentioned earlier] that the licenses have this 3 layer design. I spent more time explaining that than I care to think about, and was still doing so in 2011 as I prepared to leave CC.
I just found the Github repo and resurrected a visualization of the license layers that Alex and I created.
I told you I was really into figuring out CSS.