Now, overall, this means that I have to do a fair amount of guessing, and a fair amount of documentation reading and Strix drive_hacks writing for each drive I want to properly support. Hopefully I can make it work in a not-terrible way. (As if.)
If we look at #5...

So here, we have a slightly more sane 100-1, which if we look at smartctl, has a threshold of 3. So, 3% integrity is 'failure'.

This here says that the range of the normalised values are 120 to 38, so to get a percentage, you have to map 38-120 to 0-100. However, if we look at smartctl...

So, it seems that 38 is the minimum it can reach, 50 is the failing threshold, and 120 is the maximum. Doing some terrible math, that comes out at ~15% integrity being 'failure'.
There are also issues with upper or bottom limits. Without reading the specific documentation from the manufacturer, there's no way to tell where it is on a scale of failing to not failing, if it's above the threshold. For example, take this, from the Kingston documentation.
The normalised values have a bit of inane screwery in them, too. First of all, you can't use it for every attribute. Not every attribute has a normalised value, which means that you sometimes need to read the raw value instead. Sometimes, the value being higher is better (I'm assuming that this might be a problem for performance-related attributes). And sometimes, there just isn't a threshold.
The normalised value is a small bastion of relative sanity in the extended rotten bong-hit that is wading through SMART. You get three values - its normalised value, its worst-ever value, and the threshold that it considers is 'failing'. This means that you can (more or less) say that if it is below that, the disk is screwed. However! This isn't all of it.
Another problem is, 'what do I look at'? I basically have to go through, and look at each value, and decide whether I want to read and display the raw value (which can sometimes be in the millions for some weird-ass inane reason), or if I want to read the normalised value.
So basically, what I have to do in Strix, is let smartctl spit out these weird and terrible different values, and then attempt to normalise them in Strix. Either that, or play smartctl's stupid game and provide things like -v 9,raw24(raw8),Power_On_Hours on the command line that force every drive to have some sane common things.
Why?
Well, with every standard that doesn't have everything explicitly specified, every manufacturer will screw with it.
This is what screwery Sandforce SSDs do:
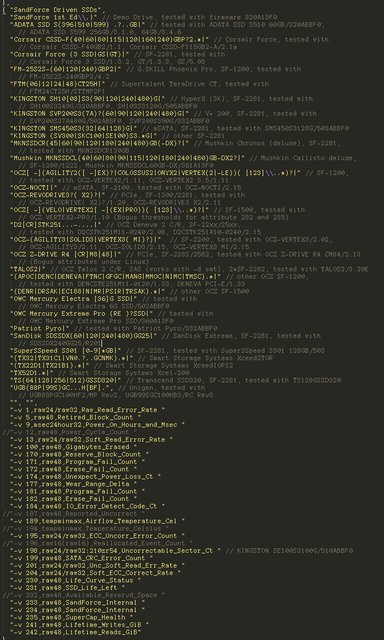
That's right. A 3,489 line, ~100KB C++ header file, with content like this:
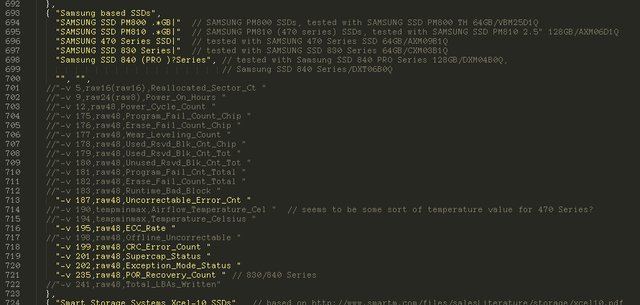
There's something called smartmontools that is basically the standard way of accessing SMART data on Linux (+ probably other platforms). How do they solve this?
SMART is not a standard, outside of the protocol. Every single manufacturer can (AND DOES!) provide their own special SMART attributes, with odd names and even odder thresholds and values. Making something to smooth this over is incredibly hard.
So basically, this is what I think happened.
Seagate, Quantum and Conner rolled by to Compaq's house one afternoon, did some skateboard tricks, then huddled into his parents' shed for a misguided teenage project. They constructed the protocol level of the standard with some spare two-by-fours nailed to a red cart, managed to get it working in a semi-okay way, and then lost interest.
Compaq then went and got trashed with Seagate and his older brother that was old enough to buy Jack Daniels, only returning to the shed at 3am with a hammer, deciding to 'finish 'er off', before throwing up onto it.
And then we had SMART.
According to the god of all knowledge, Wikipedia, SMART was "created by computer manufacturer Compaq and disk drive manufacturers Seagate, Quantum, and Conner. The disk drives would measure the disk’s "health parameters", and the values would be transferred to the operating system and user-space monitoring software. Each disk drive vendor was free to decide which parameters were to be included for monitoring, and what their thresholds should be. The unification was at the protocol level with the host."
HOWEVER, this runs into one small problem. SMART sucks. SMART really really really really sucks.
The main reason this is useful for me is that I have a number of clients with servers scattered around. They don't know what SMART is, and they don't really care, hence why they pay me. So, I have to keep an eye on SMART data, and one of Strix's goals is to do that mostly for me, and smooth over the raw numbers and give me something useful. For example, in the table, failing metrics will be a different colour, so I can have a quick glance without too much trouble.
As part of my work on Strix, I've been attempting to smooth over SMART, and provide a useful interface to the data it provides.